Research involves machine learning and deep learning algorithms for AI that predict product attribute characteristics (and quality) from large arrays of process senor data. This research is aligned with the ‘fourth industrial revolution’ also known as ‘Industrie 4.0’ where computers and automation come together with robotics using machine learning algorithms to produce products. Liao et al. (2017) suggest a huge gap exists between ‘Industrie 4.0’ laboratory experiments (95.1%) and industrial applications (4.9%). Our research program attempts to close this gap! A key aspect of this research is automated data fusion which aligns the data from process sensors with destructive testing data from the QC lab. Total quality Data Management (TqDM) principles are aligned with this research that include automated data quality assessment and imputation. The research program also has data science applications that combine the statistical process improvement method Evolutionary Operation (EVOP) with neural networks for process optimization. This research is fundamental but also applied and has been implemented in a host of applications in wood composites, engineered panels, emissions, food processing, feedstock traceability, etc. This research is a component of the interdisciplinary programs within the Bredesen Center ‘Data Science and Engineering (DSE)’ group.
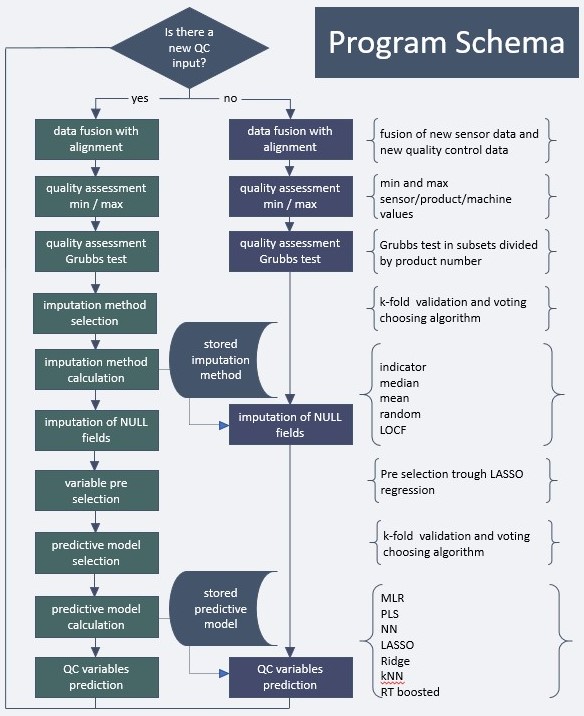
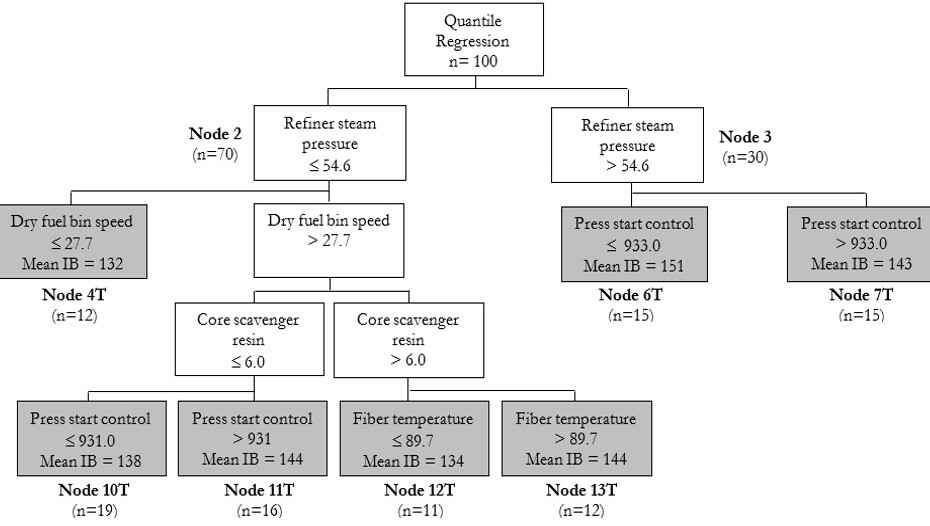
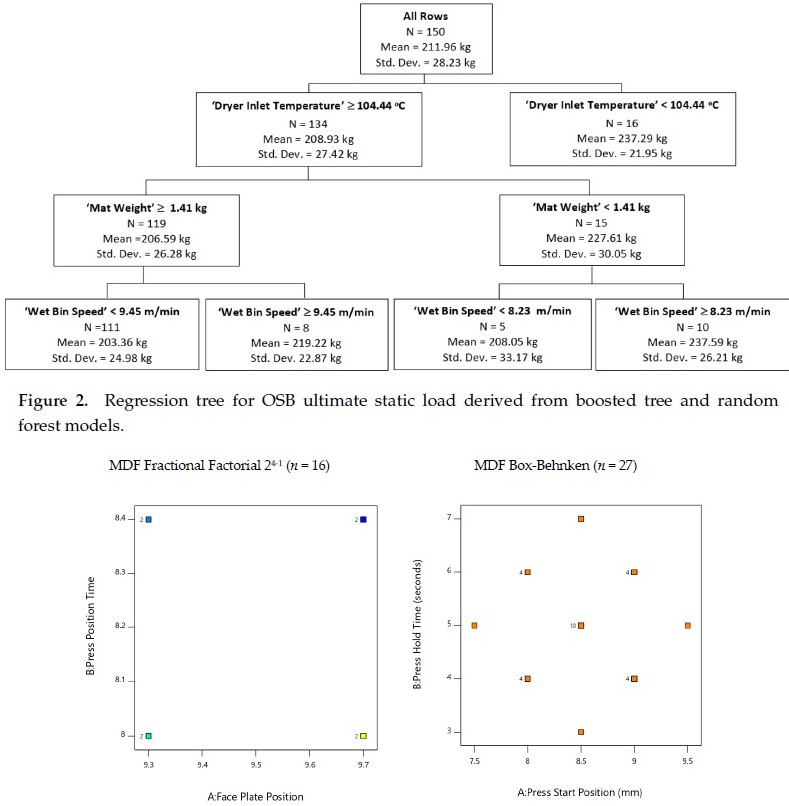

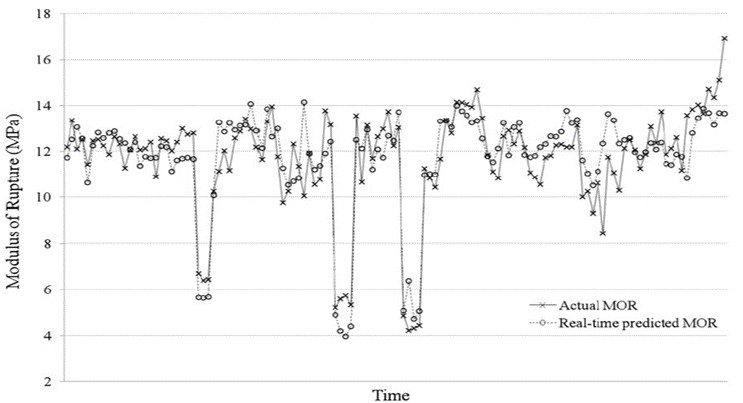
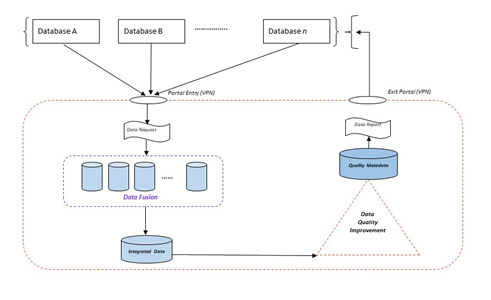
Machine learning and deep learning algorithms are used to make real-time predictions of industrial processes. This is fundamental to Industrie 4.0. A key element of this research is the development of automated data fusion algorithms from large arrays of process sensors that are aligned in the proper time-order in a process for the data that are associated with the product quality attribute metrics. Machine learning algorithms such as ‘Random Forests’, ‘Boosted Trees’, and ‘Bayesian Additive Regression Trees (BART)’ are used as an ensemble to improve the accuracy of predictions.

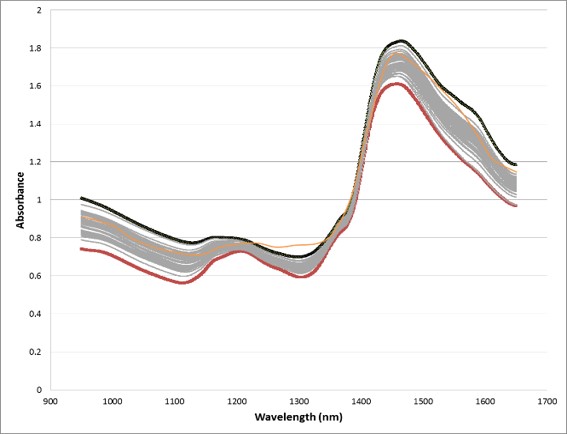
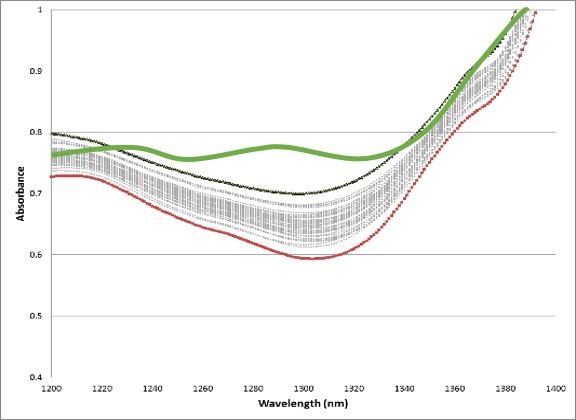

The research in machine learning also investigates developing new statistical methods for ‘data signatures’ or ‘data footprints.’ The ability to detect special-cause variation of incoming feedstocks from advanced sensor technology is invaluable to manufacturers. Many on-line sensors produce data signatures that require further off-line statistical processing for interpretation by operational personal. However, early detection of changes in variation in incoming feedstocks may be imperative to promote ‘early-stage’ preventive measures. Control bands based on pointwise prediction intervals constructed from the ‘Bonferroni Inequality’ and Bayesian smoothing splines are illustrated in the figures above.
Resources:
Mill Application (YouTube Video)
Publications of Interest:
Young, T.M., R.A. Breyer, T. Liles, A. Petutschnigg. 2020. Improving innovation from science using kernel tree methods as a precursor to designed experimentation. Applied Sciences. 10(10):3387. https://doi.org/10.3390/app10103387
Young, T.M., O. Khaliukova, N. André, A. Petutschnigg, T.G. Rials, C.-H. Chen. 2019. Detecting special-cause variation ‘events’ from process data signatures using control bands. Journal of Applied Statistics. 46(16):3032-3043. https://doi.org/10.1080/02664763.2019.1622658
Zeng, Y., T.M. Young, D.J. Edwards, F.M. Guess, C.-H. Chen. 2016. Case studies: A study of missing data imputation in predictive modeling of a wood composite manufacturing process. Journal of Quality Technology. 48(3):284-296. https://doi.org/10.1080/00224065.2016.11918179
Young, T.M., R.V. León, C.-H. Chen, W. Chen, F.M. Guess, D.J. Edwards. 2015.Robustly estimating lower percentiles when observations are costly. Quality Engineering. 27:361-373. https://doi.org/10.1080/08982112.2014.968667